K-Means
k-means clustering partitions a multi-dimensional data set into k clusters, where each data point belongs to the cluster with the nearest mean, serving as a prototype of the cluster.
K-means is often referred to as Lloyd’s algorithm. In basic terms, the algorithm has three steps. The first step chooses the initial centroids, with the most basic method being to choose samples from the dataset . After initialization, K-means consists of looping between the two other steps. The first step assigns each sample to its nearest centroid. The second step creates new centroids by taking the mean value of all of the samples assigned to each previous centroid. The difference between the old and the new centroids are computed and the algorithm repeats these last two steps until this value is less than a threshold. In other words, it repeats until the centroids do not move significantly.
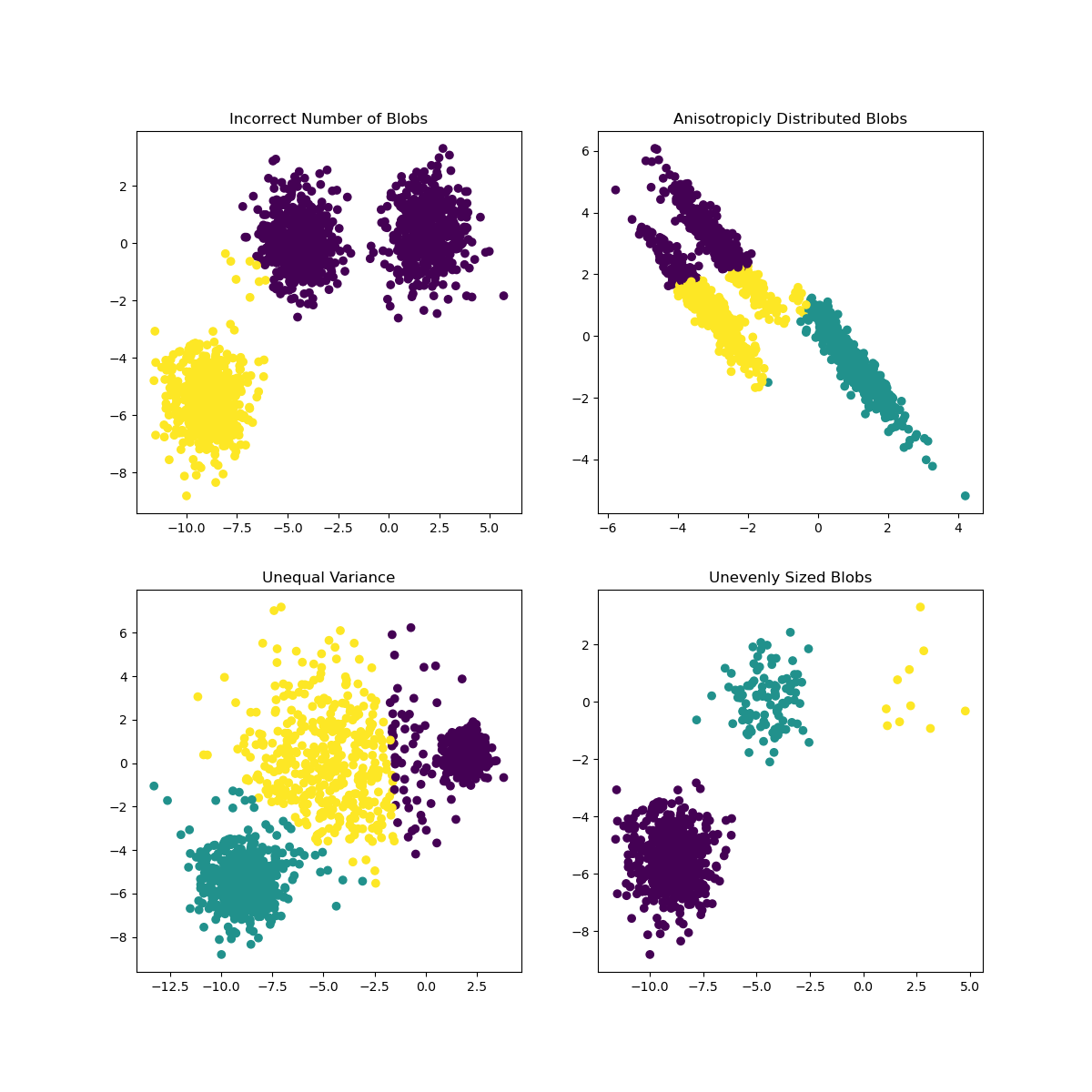
- When you have numeric, multi-dimensional data sets
- You don’t have labels for your data
- You know exactly how many clusters you want to partition your data into
Example
import (
"github.com/geoos/clusters/kmeans"
"github.com/geoos/clusters"
)
// set up a random two-dimensional data set (float64 values between 0.0 and 1.0)
var d clusters.PointList
for x := 0; x < 1024; x++ {
d = append(d, clusters.Coordinates{
rand.Float64(),
rand.Float64(),
})
}
// Partition the data points into 16 clusters
km := kmeans.New()
clusters, err := km.Partition(d, 16)
for _, c := range clusters {
fmt.Printf("Centered at x: %.2f y: %.2f\n", c.Center[0], c.Center[1])
fmt.Printf("Matching data points: %+v\n\n", c.Observations)
}DBScan
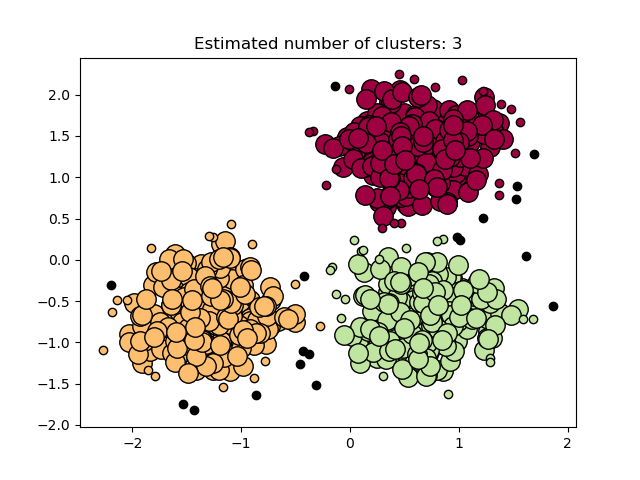
(Lat, lon) points fast clustering using DBScan algorithm in Go.
Given set of geo points, this library can find clusters according to specified params. There are several optimizations applied:
- distance calculation is using “fast” implementations of sine/cosine, with sqrt being removed
- to find points within eps distance k-d tree is being used
- edge case handling of identical points being present in the set
Example
Build list of points:
```
points := cluster.PointList